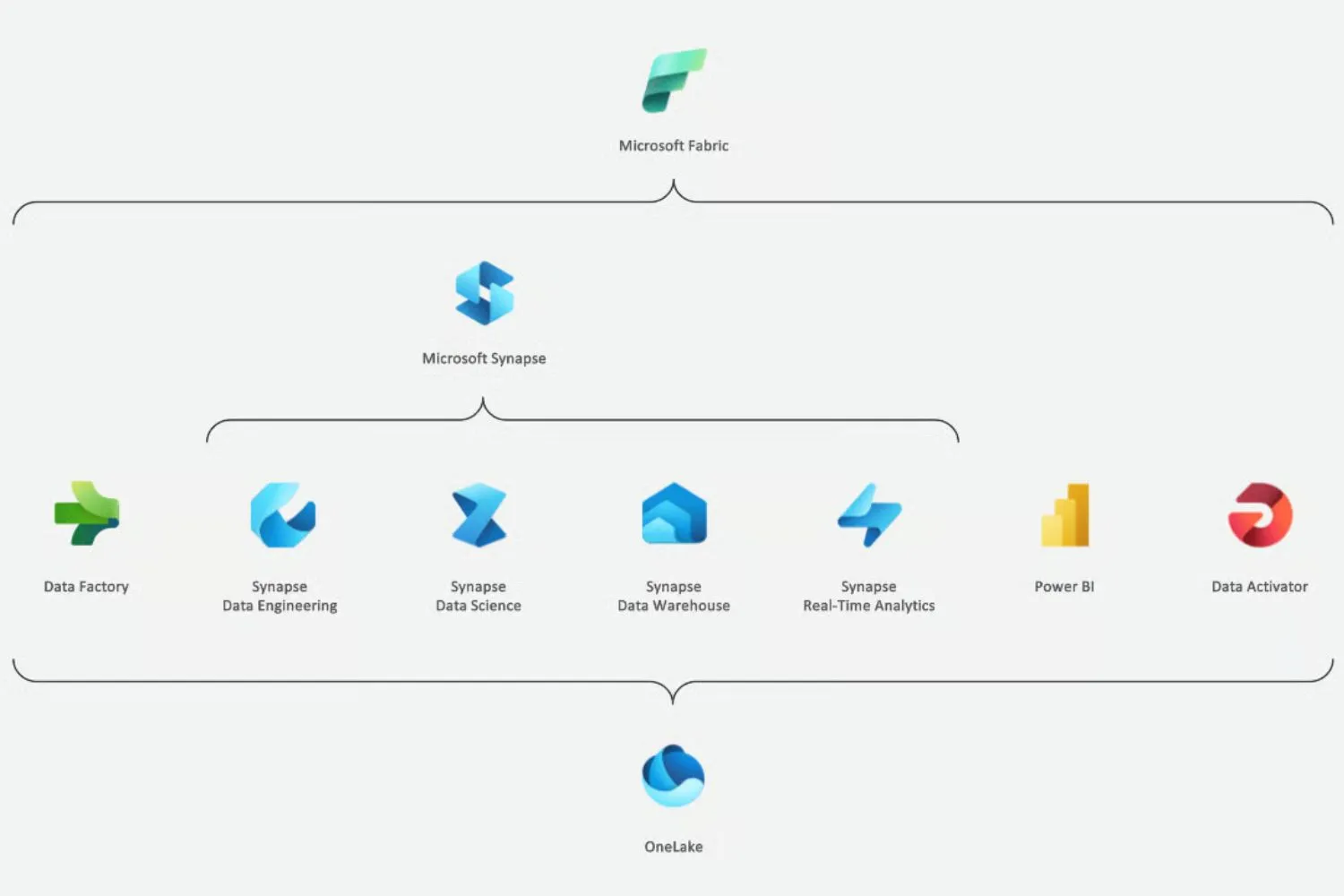
O Microsoft Fabric é uma plataforma de análise end-to-end que unifica ferramentas conhecidas (Synapse, Data Factory, Power BI) em um único ambiente SaaS.
A ideia é diminuir atritos entre times: engenharia, ciência de dados e analistas conseguem trabalhar no mesmo espaço, com OneLake como núcleo para os dados.
Conteúdo
Por que o Fabric importa para quem faz Engenharia de Dados?
Esse projeto deixou de ser conceito em 2023 e entrou em disponibilidade geral, acelerando adoção em projetos corporativos que precisam integrar ETL, lakehouse, ML e relatórios interativos.
Para quem trabalha com dados, é uma plataforma que promete reduzir movimentação desnecessária de dados e simplificar arquitetura.
O Fabric reúne workloads que já conhecemos, engenharia de dados em Spark, data warehousing em SQL, integração com Data Factory e visualização pelo Power BI, mas faz isso dentro de um fluxo integrado.
Isso vira vantagem quando o objetivo é entregar insights rápidos com governança e segurança corporativa.
Na prática, menos “costura” entre ferramentas significa menos falhas no pipeline. Equipes conseguem prototipar no mesmo workspace, usar notebooks para experimentos e, quando pronto, operacionalizar com pipelines escaláveis.
Para empresas que buscam velocidade com controle, essa integração tem impacto direto no time-to-value.
Principais componentes do Fabric (visão rápida)
- Data Engineering (Synapse) — processamento em Spark para ETL e transformações em escala.
- Data Factory (integração) — orquestração, Power Query e atividades de ingestão.
- Data Warehouse (Synapse SQL) — armazém com performance SQL.
- Real-time Intelligence — consultas e analytics em tempo real.
- Data Science — integração com Azure ML para treinar e rastrear modelos.
- Power BI — camada de visualização e storytelling para tomada de decisão.
Cada peça é uma experiência pensada para um perfil (eng. de dados, cientista, analista, citizen).
Mas elas se conectam via OneLake e via objetos compartilhados (tabelas, arquivos Delta, modelos semânticos). Isso facilita governança e reutilização.
Engenharia de Dados no Fabric
A área de Data Engineering no Fabric oferece os itens práticos que um engenheiro precisa: lakehouses, pipelines, definições de trabalho Spark e notebooks interativos.
É a camada onde dados brutos viram tabelas confiáveis para consumo.
Na home de engenharia de dados você cria lakehouses, desenha pipelines para mover dados para o lake, submete jobs Spark (batch ou streaming) e usa notebooks para escrever e testar código (Python, Scala, Spark SQL).
Tudo isso dentro do workspace colaboração nativa.
Lakehouse
O lakehouse é a arquitetura que unifica dados estruturados e não estruturados no mesmo local, suportando consultas SQL, processamento em Spark e consumo por ML e BI.
Ele é pensado para ser o ponto único de verdade (single source of truth) em muitos projetos.
Na prática, um lakehouse reduz duplicação, melhora descoberta de dados e facilita políticas de acesso.
Se você já lidou com silos (silos de arquivos, silos de tabelas, silos de relatórios), o lakehouse é a primeira resposta arquitetural.
Notebooks e definições de trabalho Spark
Os notebooks do Fabric são ambientes interativos para desenvolvimento: documentação, código e visualizações no mesmo lugar.
Eles são usados tanto por engenheiros (ingestão e transformação) quanto por cientistas (experimentos, treinamento de modelos).
As definições de trabalho Spark permitem orquestrar jobs em cluster: você configura fontes, transformações e destinos e executa em modo batch ou streaming.
Isso facilita a produção de pipelines confiáveis, escaláveis e reprodutíveis.
Data Factory no Fabric
O Data Factory no Fabric combina Power Query (experiência familiar para quem usa Power BI) com a escala de um serviço de integração.
É aqui que você faz ingestão, transformações “ligth” e orquestração entre workloads.
Para cenários comuns: copiar dados de um banco legado, enriquecer com transformações em Spark, escrever em tabelas Delta do lakehouse e, por fim, disponibilizar para um modelo semântico ou relatório Power BI, tudo orquestrado por pipelines do Data Factory.
Exemplos práticos de uso (cenários reais)
Exemplo 1 — Modernização de ETL legado
Uma empresa com ETLs em servidores on-premise pode migrar ingestão para pipelines do Fabric, usar Spark para transformação e consolidar o resultado em Lakehouse. Resultado: menor latência e manutenção simplificada.
Exemplo 2 — Projeto de ML integrado
Dados chegam via Data Factory, são preparados em notebooks, modelos são treinados com Azure ML integrado e os resultados ficam disponíveis em tabelas do lakehouse para visualização no Power BI. Dessa forma, o ciclo de experimentação vira produção com menor esforço.
Considerações sobre custo, governança e carreira
Custo: o Fabric traz um modelo de capacity/pool que unifica consumo de vários workloads.
Isso pode simplificar controle, mas exige planejamento de capacidade para evitar surpresas na conta. Governança e catalogação devem ser consideradas desde o início.
Para o profissional de dados, aprender Fabric é investir em versatilidade.
Se você já trabalha com Power BI, Synapse ou Data Factory, a transição tende a ser natural. Se vem do mundo do Python e Spark, a vantagem é ter um espaço integrado para levar protótipos ao produto.







