
Quando falamos em análise de dados, um dos maiores desafios é garantir que as informações estejam organizadas, limpas e prontas para serem usadas. Afinal, dados sem um bom processo de transformação não geram insights úteis.
É aqui que entra o Fluxo de Dados Gen2 no Microsoft Fabric, uma solução que melhora a forma como coletamos, processamos e estruturamos os dados para projetos de Business Intelligence (BI).
Com essa tecnologia, tarefas que antes eram demoradas e manuais se tornam mais simples e otimizadas. Isso impacta diretamente na agilidade da tomada de decisão, pois os dados chegam mais rápido e melhor estruturados às análises.
Conteúdo
O que é o Fluxo de Dados Gen2 no Microsoft Fabric?
O Fluxo de Dados Gen2 é uma evolução do tradicional Fluxo de Dados do Power BI (Gen1), trazendo novos recursos e uma experiência mais intuitiva.
Ele permite a criação de fluxos de dados dentro do Microsoft Fabric, oferecendo maior flexibilidade e desempenho para transformar e preparar informações antes de carregá-las em um modelo de BI.
Comparado ao Fluxo de Dados Gen1, a nova versão trouxe melhorias importantes, como:
- Criação de fluxo mais curta e eficiente: menos etapas para configurar e processar dados.
- Salvamento automático e publicação em segundo plano: evita perda de progresso ao trabalhar com transformações.
- Melhor monitoramento e histórico de atualizações: facilita o acompanhamento e ajustes nos fluxos de dados.
- Integração aprimorada com pipelines de dados: permitindo automação mais robusta.
Esses avanços tornam o Fluxo de Dados Gen2 uma ferramenta essencial para quem trabalha com análise de dados e precisa de processos mais organizados e escaláveis dentro do Microsoft Fabric.
Criando um Fluxo de Dados Gen2 no Microsoft Fabric
O Fluxo de Dados Gen2 é uma ótima solução dentro do Microsoft Fabric para transformar, organizar e carregar dados em projetos de BI.
Ele permite consolidar informações de diferentes fontes, automatizar processos de extração e garantir que os dados estejam prontos para análise de forma eficiente.
Vamos ver como configurar e criar um fluxo de dados do zero.
Pré-requisitos: configuração do Power BI Gateway
Antes de começar, é importante garantir que o Power BI Gateway esteja instalado e configurado corretamente, para baixar clique aqui.
O gateway permite conectar fontes de dados locais ao Microsoft Fabric, possibilitando a extração de informações de bancos de dados como SQL Server e arquivos locais.
Passo a passo para instalar o gateway
- Baixe o gateway padrão no site da Microsoft.
- Execute o instalador, mantenha o caminho padrão, aceite os termos de uso e clique em Instalar.
- Após a instalação, insira o email da sua conta do Office 365 e clique em Entrar.
- Selecione Registrar um novo gateway neste computador e clique em Avançar.
- Escolha um nome único para o gateway e defina uma chave de recuperação (essa chave será necessária caso precise recuperar ou mover o gateway).
- Clique em Configurar e finalize o processo.
Observações importantes
- Se o gateway precisar acessar fontes de dados em outro domínio, ele deve ser instalado em um computador que tenha uma relação de confiança com esse domínio.
- Guarde sua chave de recuperação em um local seguro. A Microsoft não tem acesso a ela e não pode recuperá-la.
- O gateway pode ser usado com Power BI, Power Apps e Power Automate.
Mais informações
A Microsoft pode atualizar esse processo no futuro. Para conferir sempre a versão mais recente, acesse a documentação oficial clicando aqui.
Passo a passo para criar um Fluxo de Dados no Fabric utilizando Power Query

- No Microsoft Fabric, vá até a área de Dados e selecione Criar um novo Fluxo de Dados.
- Escolha Iniciar com um Conjunto de Dados ou Criar um Fluxo de Dados do zero.
- Selecione a fonte de dados que deseja conectar (SQL Server, Excel, APIs etc.).
- Utilize o Power Query para transformar os dados, aplicando filtros, ajustes e cálculos conforme necessário.
- Defina a tabela final e salve as alterações.
- Publique o fluxo de dados para que ele possa ser utilizado em relatórios e dashboards.
Esse processo garante que os dados estejam prontos para análise, permitindo reutilização e automação do pipeline de dados.
Construção do Fluxo de Dados do Projeto Car Sales
Para entender melhor como funciona na prática, vamos analisar um caso real: o Projeto Car Sales, que envolve a análise de dados de vendas e devoluções de veículos.
Visão geral do projeto e sua necessidade de análise de dados
O projeto tinha como objetivo consolidar informações de vendas de veículos, devoluções e metas comerciais, permitindo uma visão clara do desempenho ao longo do tempo.
As fontes de dados eram:
- Banco de dados SQL Server, onde estavam armazenadas as tabelas de vendas, devoluções e dimensões.
- Arquivo Excel, contendo as metas de vendas por mês e ano..
A integração dessas fontes permitiria um acompanhamento detalhado dos resultados e ajudaria na tomada de decisões estratégicas.
Utilização do Power Query para transformar e estruturar os dados
Algumas transformações foram feitas no SQL Server, como união das tabelas de vendas e devoluções, porém outras foram realizadas no Power Query, para garantir que os dados estivessem prontos para análise:
- Tratamento dos dados do arquivo Excel de metas comerciais.
- Criação da tabela dCalendario através de script.
Essas transformações facilitaram a análise e garantiram que os dados fossem integrados corretamente.
Integração com SQL Server e Excel: como combinar múltiplas fontes de dados
A integração foi feita no Fluxo de Dados Gen2, garantindo que as informações fossem extraídas, transformadas e carregadas automaticamente.
- A conexão com o SQL Server trouxe os dados brutos de vendas e devoluções.
- O arquivo Excel foi importado para cruzamento com as vendas e análise de metas.
- O Power Query foi utilizado para padronizar os formatos e realizar as junções necessárias.
Essa abordagem garantiu um fluxo de dados centralizado e automatizado.
Criação da dimensão dCalendário dinâmica
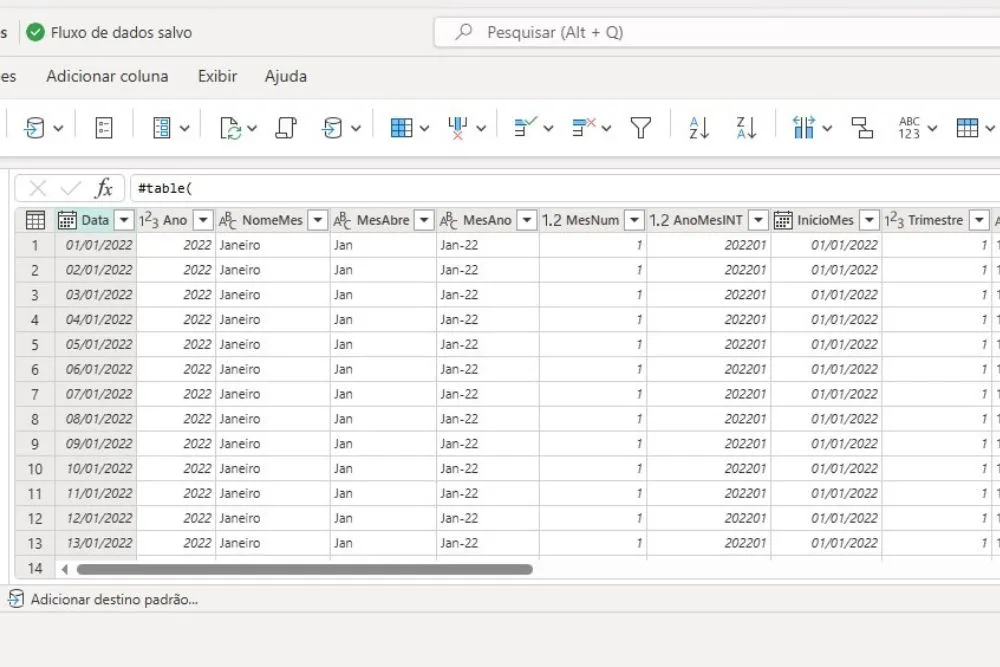
Para permitir análises temporais mais detalhadas, foi criada uma dimensão dCalendário dinâmica dentro do fluxo de dados.
- Foi utilizado um script de Power Query, ajustando os parâmetros de data inicial e final com base na coluna data da View fVendas, esse mesmo script eu utilizo em outros projetos.
- A integração com o site da ANBIMA trouxe informações de feriados nacionais, garantindo maior precisão nas análises.
Essa dimensão foi essencial para permitir filtros avançados e facilitar a comparação de períodos no relatório final.
Monitoramento e Manutenção do Fluxo de Dados Gen2
Criar um Fluxo de Dados Gen2 no Microsoft Fabric é apenas o começo. Para garantir que ele continue funcionando de maneira eficiente, é essencial implementar práticas de monitoramento, manutenção e otimização.
Monitoramento de Atualizações e Histórico de Mudanças
O Microsoft Fabric fornece ferramentas para acompanhar o desempenho e as atualizações dos fluxos de dados.
Monitorar essas mudanças é essencial para evitar falhas e garantir que os dados processados estejam sempre atualizados.
Para fazer isso:
- Acompanhe os logs de execução – No painel do Microsoft Fabric, é possível visualizar um histórico das execuções do fluxo de dados, incluindo tempo de processamento e possíveis erros.
- Configure alertas – Utilize notificações para ser informado sobre falhas ou atrasos no processamento dos dados.
- Valide os dados regularmente – Erros podem surgir em qualquer etapa do pipeline, por isso é importante criar processos de validação para garantir a integridade das informações.
Integração com Pipelines de Dados para Automação de Processos
O Microsoft Fabric oferece diversas opções para automatizar fluxos de dados, tornando o processamento mais eficiente.
No entanto, para este projeto, optei por um fluxo de dados mais simples e direto, já que ainda estou explorando as possibilidades da ferramenta.
Mesmo assim, é importante destacar que o Fabric permite uma automação mais avançada, caso necessário.
Algumas das formas de automação disponíveis incluem:
- Agendamento de atualizações – Permite definir horários específicos para que o fluxo de dados seja atualizado automaticamente, garantindo que as informações estejam sempre atualizadas.
- Integração com notebooks de Python ou Spark – Ideal para projetos mais avançados, como aplicações de machine learning e transformações complexas de dados.
- Conexão com o Microsoft Fabric Data Factory – Facilita a criação de pipelines automatizados que integram diversas fontes e destinos de dados.
Essas opções tornam o Fluxo de Dados Gen2 ainda mais poderoso, permitindo que ele se adapte a diferentes necessidades.
Para este projeto, foquei em uma abordagem mais prática, mas vejo um grande potencial para explorar essas integrações em trabalhos futuros.
Boas Práticas para Manter o Fluxo de Dados Eficiente e Otimizado
Para evitar gargalos e manter um desempenho alto, algumas boas práticas podem ser adotadas na criação e manutenção do Fluxo de Dados Gen2:
Evite carregar dados desnecessários – Filtre as informações antes de carregá-las no fluxo de dados para reduzir o tempo de processamento.
Utilize tabelas incrementais – Sempre que possível, opte por carregar apenas novos registros em vez de processar toda a base novamente.
Organize os dados corretamente – Estruture as tabelas e colunas de forma otimizada para facilitar consultas e relatórios.
Monitore a performance – Analise o tempo de execução e ajuste o fluxo conforme necessário para evitar sobrecarga de processamento.
Seguindo essas práticas, o fluxo de dados será mais ágil, confiável e pronto para suportar demandas analíticas cada vez maiores.
Conclusão sobre Como Criei um Fluxo de Dados Gen2 no Microsoft Fabric para Análise de Vendas no Projeto Car Sales
Explorei como o Fluxo de Dados Gen2 no Microsoft Fabric pode transformar a forma como trabalhamos com dados.
Desde a criação do fluxo até sua integração com diferentes fontes e o monitoramento contínuo, ficou evidente o quanto essa tecnologia facilita a preparação e transformação de dados para projetos de BI e análise de dados.
Para testar na prática, utilizei essa solução no projeto Car Sales, onde precisei estruturar um fluxo de dados. O desafio era integrar dados de múltiplas fontes, como SQL Server e planilhas Excel, garantindo que as informações fossem atualizadas e otimizadas para visualização no Power BI.
O Fluxo de Dados Gen2 foi essencial para organizar e transformar esses dados, aplicando regras de limpeza, unificação e a criação de uma dimensão dCalendário.
Minha jornada com o Microsoft Fabric não termina aqui, mesmo conquistando a certificação DP-600 na plataforma, o que me permitiu aprofundar ainda mais no seu funcionamento e entender melhor seu potencial, ainda há muito a explorar.
Assim como o Databricks se tornou referência em Big Data e Machine Learning, acredito que o Fabric seguirá o mesmo caminho nos próximos anos.
O Microsoft Fabric veio para transformar a análise de dados, e seguir explorando suas possibilidades será essencial para acompanhar a evolução do mercado.







